Discover Your Next Favorite Movie: Building a Python-Based Movie Recommendation System

Sick of endlessly pondering which movie to watch? Say goodbye to decision paralysis, my fellow movie enthusiasts! Get ready to embark on an exciting journey as we demystify the art of creating a movie recommendation system using Python. Imagine a world where movies effortlessly find you, like a best friend with an uncanny ability to know your taste. Buckle up, grab your popcorn, and let's dive into the wonderful realm of Python-powered movie suggestions. Get ready for movie nights that will leave you grinning from ear to ear!
PS: If you are reading this, I assume that you have a sufficient understanding of Python as well as basic data preprocessing techniques
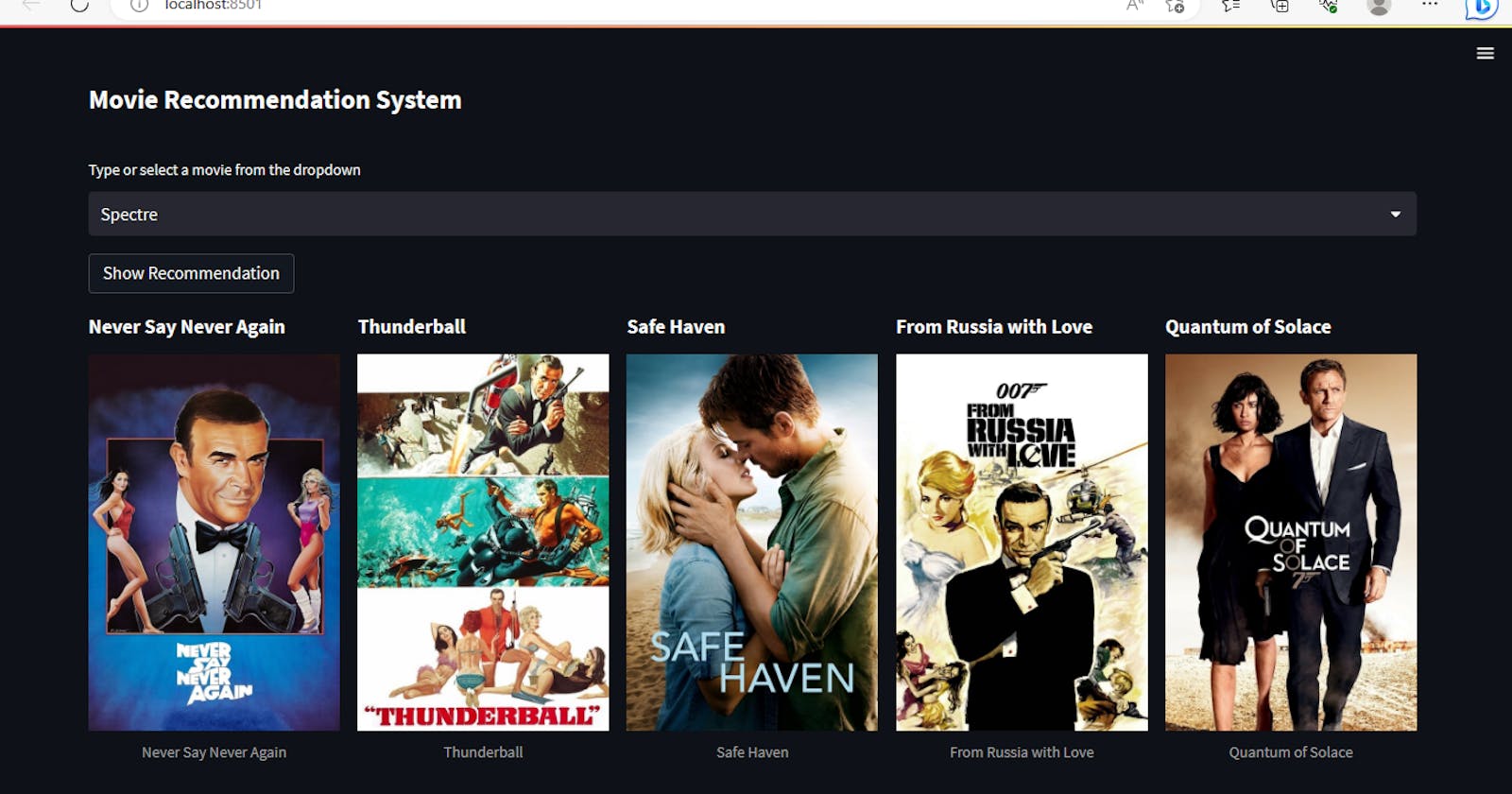
Get ready to unlock the secrets of movie recommendations as we embark on a journey to build our very own Netflix-inspired recommendation system. In this article, I'll be your companion, guiding you through the fascinating process step by step. Armed with Python and the clever concept of cosine similarity, we'll unravel the mysteries behind the movie magic. So, grab your favorite movie snack, settle into your comfiest seat, and let's dive into the captivating world of building a movie recommendation system that will have you shouting, "Pass the popcorn, please!"
Here's the link to the dataset we'd be working with: https://www.kaggle.com/datasets/tmdb/tmdb-movie-metadata
Let's jump right into it! To start building our movie recommendation system, we need to import the necessary modules and load our datasets. In Python, we'll be relying on modules like pandas, numpy, and scikit-learn to handle the data manipulation and calculations. As for the datasets, we'll be working with a collection of movies and user ratings. So, let's bring those modules on board and load up our datasets.

Our next step in building our movie recommendation system is to merge the movies and credits data frames. Think of it as a cinematic rendezvous where the movie details and the cast and crew come together for a grand collaboration.
By merging the data frames on the title column, we create a unified view that combines all the relevant information. This means that rows with matching movie titles will be merged into a single row, incorporating the columns from both data frames. The result? A comprehensive snapshot of each movie that includes not only its details but also the corresponding information about the cast and crew involved.
This merging process is vital for our recommendation system as it allows us to consider various factors, such as genre, release year, and the people behind the scenes when suggesting movies to our users.

Now that we've done that, we'd do some basic preprocessing.
Preprocessing the data is a crucial step in preparing it for our movie recommendation system. It helps us clean, transform, and refine the data to ensure optimal performance. Show us your preprocessing prowess, and let's dive into the exciting world of data preparation!
Removing Duplicates: We'll start by checking for and removing any duplicate rows in our merged data frame. Duplicates can skew our recommendations, so we want to ensure each movie has a single representation.
Handling Missing Values: Next, let's address any missing values in our data frame. Missing data can impact the accuracy of our recommendations, so we'll decide how to handle them. Options include removing rows with missing values or filling in the missing values with appropriate substitutes.
Feature Selection: For our recommendation system, we need to identify the relevant features that contribute to making accurate recommendations. Features like movie genre, director, and actors often play a significant role. Let's select the most informative features and remove any unnecessary ones.
Encoding Categorical Variables: Since our recommendation system operates on numerical data, we'll need to convert categorical variables, such as movie genres, into a numerical representation. This process, called encoding, ensures compatibility with the algorithms we'll be using.
Feature Scaling: To avoid bias towards certain features, we'll perform feature scaling. This process brings all numerical features to a similar scale, preventing any one feature from dominating the recommendation process.
Once we've completed these preprocessing steps, our data will be primed and ready for the magic of our movie recommendation system. So, roll up your sleeves, show us your data preprocessing skills, and let's transform our data into a masterpiece!
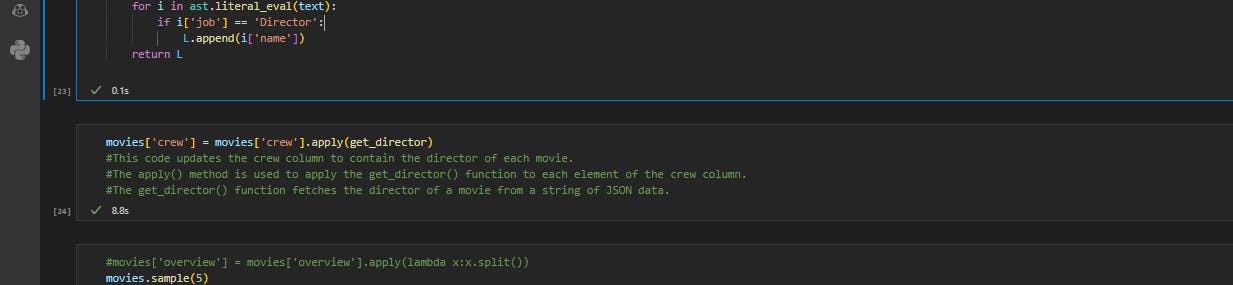
Up next, we'd introduce a handy Python function called get_director that plays a key role in extracting the director(s) of a movie from a JSON string. This function brings simplicity and efficiency to the process.
To begin, we'd need the ast module. Which we've imported earlier, which provides useful functions for working with Python data structures, including the invaluable literal_eval(). This function allows us to evaluate the JSON string and convert it into a Python object, opening the door to seamless data manipulation.
Inside the get_director function, we create a list called L, serving as a container for the discovered directors. The function then diligently traverses the JSON data, examining each person's entry. If a person's job is identified as 'Director', their name is added to the L list, ensuring we capture the directorial talent associated with the movie.
Upon completion of the iteration, the get_director function proudly presents the L list, brimming with the names of all the directors extracted from the JSON data.
This robust function grants us the ability to effortlessly retrieve the director(s) of a movie, a vital piece of information that significantly enhances the accuracy and precision of our recommendation system. By leveraging the power of Python and this nifty function, we can delve deeper into the creative minds behind each movie and offer more personalized and insightful recommendations.

Easy right? Great! If it's not, hang in there, I'll leave a link to my github repo at the end of the article.
Now, let's move on to the next step: defining the "collapse" function. This Python function is designed to collapse a list of strings into a single string. Here's a breakdown of how the function works:
To begin, the function creates a new list called L1, which will serve as the container for the collapsed strings.
Next, the function iterates over the given list of strings, denoted as L. For each string in L, the function removes all the spaces within the string using the replace() method. This effectively collapses the string into a continuous sequence of characters.
The collapsed string is then appended to the L1 list.
Lastly, the function returns the L1 list, which now holds the collapsed strings.
With the "collapse" function in place, we can effortlessly convert a list of strings into a single string, ensuring a streamlined and consolidated representation of the data.

After this, the process is quite straightforward.
Compute the item-item similarity matrix The heart of our recommendation system lies in calculating the item-item similarity matrix using cosine similarity. This matrix measures the similarity between each pair of movies based on their feature vectors. By comparing movies using cosine similarity, we can identify those with similar characteristics, which often leads to relevant recommendations.
Generate movie recommendations With the similarity matrix in hand, it's time to generate movie recommendations for a specific user. This can be done by selecting movies the user has already rated highly and identifying similar movies based on their cosine similarity scores. By recommending similar movies, we aim to cater to the user's preferences and increase their engagement with our recommendation system.
Evaluate and refine the recommendation system Once we have our initial recommendations, it's important to evaluate the performance of our recommendation system. This can be done using various metrics, such as precision, recall, or mean average precision. Based on the evaluation results, we can fine-tune our system by adjusting parameters or incorporating additional features to improve the accuracy and quality of the recommendations.
Deploy and iterate After refining our recommendation system, we are ready to deploy it and put it to the test with real users. Monitor user feedback and behavior to gather insights and make further improvements. Remember, the iterative process of refining and enhancing the recommendation system is essential for delivering personalized and valuable movie suggestions.
By following these steps, you'll be on your way to building a highly effective movie recommendation system. However, since this article aims to provide a concise overview, we have omitted some of the finer details. If you're interested in a more comprehensive explanation and detailed implementation, I recommend checking out my GitHub repository https://github.com/Izuasomba/Movie-recommendation-system. In the repository, you'll find a thorough explanation of each step, along with the complete code and additional resources to enhance your understanding. Feel free to explore the repository to gain a deeper insight into building your very own movie recommender system using cosine similarity, I wish you the best of luck.